L’implémentation de la prédiction du taux d’attrition (churn) consiste à identifier les clients les plus susceptibles de quitter une entreprise à la fin de leur contrat, afin de pouvoir leur proposer une offre de rétention ciblée. Dans R, ce problème est traité comme une tâche de classification ou d’estimation de probabilité de classe, car l’objectif est de prédire une variable catégorielle (le client part ou reste).
Voici les étapes clés pour implémenter cette prédiction avec R, en s’appuyant sur l’apprentissage supervisé :
1. Préparation des données et sélection des attributs Avant la modélisation, il est crucial de rassembler des données historiques (l’âge, les revenus, l’utilisation du service, les appels au service client, etc.) où la cible (le départ effectif du client) est déjà connue. Les packages R dplyr et tidyr facilitent le nettoyage et la manipulation de ces ensembles de données complexes. Ensuite, pour identifier les variables les plus prédictives, on utilise des métriques comme le gain d’information (basé sur l’entropie). Dans des exemples pratiques sur le churn, des variables comme la valeur du logement du client ou les dépassements de forfait s’avèrent souvent avoir un gain d’information plus élevé que le niveau de satisfaction déclaré.
2. Scission des données et choix de l’algorithme dans R Afin d’éviter le surapprentissage (overfitting) où le modèle mémoriserait simplement les données sans pouvoir généraliser, le jeu de données est divisé aléatoirement en un ensemble d’entraînement (pour construire le modèle) et un ensemble de test ou de validation (pour évaluer son efficacité). Vous pouvez implémenter plusieurs algorithmes via R :
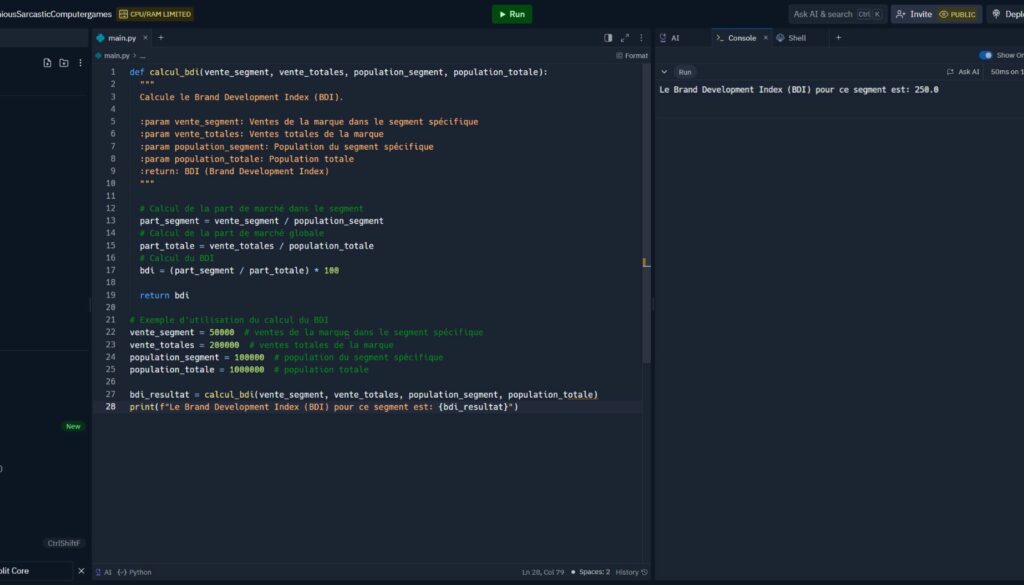
- Régression Logistique : Elle modélise la probabilité (les log-odds) qu’un client résilie. Dans R, on utilise la fonction native
glm()en spécifiant la distribution binomiale :glm(formule, family=binomial(link="logit"), data=mydata). - Arbres de Décision : Ils segmentent les clients de manière récursive en sous-groupes partageant des probabilités d’attrition similaires, ce qui donne des règles très intelligibles. Le package rpart de R permet de les générer avec la fonction
rpart(). L’arbre obtenu peut ensuite être simplifié via la fonctionprune()pour améliorer sa capacité de généralisation. - Forêts Aléatoires (Random Forests) : Cette méthode d’ensemble crée de multiples arbres de décision pour accroître la précision des classifications. Elle s’implémente facilement avec la fonction
randomForest()du package R éponyme.
3. Évaluation de la performance Une fois le modèle entraîné, la fonction predict() de R est appliquée à l’ensemble de test pour vérifier comment le modèle réagit face à de nouvelles données. Pour évaluer la qualité du modèle, plusieurs méthodes sont indispensables :
- La matrice de confusion : Elle croise les prédictions (ex : le modèle dit « va partir ») avec la réalité (le client est effectivement parti), permettant d’extraire les taux de vrais positifs, faux positifs, etc..
- Les métriques de précision : R permet de calculer la sensibilité, la spécificité ou encore l’accuracy globale. Attention toutefois, dans le cas du churn où les départs sont minoritaires (déséquilibre des classes), l’accuracy seule est souvent trompeuse.
- Les visualisations graphiques : Les courbes ROC, de Lift et de Profit permettent de comparer visuellement plusieurs modèles (par exemple comparer la performance d’un arbre
rpartface à une régressionglm) et d’ajuster le seuil de probabilité déclenchant l’offre de rétention.
4. Intégration au Cadre de la Valeur Attendue (Expected Value) L’erreur courante est de vouloir cibler uniquement les clients ayant la plus forte probabilité mathématique de partir. En entreprise, le vrai problème n’est pas le départ du client en soi, mais la perte financière associée. L’étape finale consiste à coupler les probabilités issues de R avec une équation de Valeur Attendue intégrant les coûts et bénéfices de l’offre de rétention. La décision optimale cible les clients pour lesquels la campagne est la plus rentable. Mathématiquement, on cherche à maximiser le gain : VT=Δ(p)⋅uS(x)−c, où Δ(p) est la différence de probabilité que le client reste grâce à l’offre, uS(x) sa valeur financière s’il reste, et c le coût de la campagne. Cette étape d’ingénierie analytique exige de créer deux modèles prédictifs distincts : un estimant la probabilité que le client reste s’il est ciblé, et un autre s’il ne l’est pas.